16x AA font rendering using coverage masks, part II
This is part two in the series on 16x AA font rendering using coverage masks, as used in our profiler.
- In part one, we saw how to render glyphs in real-time using 16xAA, sampled at a regular grid.
- In this part (part two), we will see how we can move to a rotated grid and how to optimize the shader so that it collapses almost entirely into a texture read and a few table lookups.
- In part three, we will see how we can rasterize the glyphs in real-time on Compute and CPU.
Rendering a glyph with a rotated grid
Rendering glyphs using a regular sampled grid gives quite good results already for curved glyphs, like the ‘S’ letter we saw in part one. A regular grid doesn’t work equally well for glyphs with straight horizontal and vertical edges, as they will only have four unique shades in the horizontal and vertical direction. This is clearly visible when we render the letter ‘T’ using the regular grid:

In this image we can see up to four shades leading to a horizontal or vertical edge. As a lot of glyphs are built from horizontal and vertical edges (especially in western fonts), we can improve this by sampling on a rotated grid instead of a regular grid:
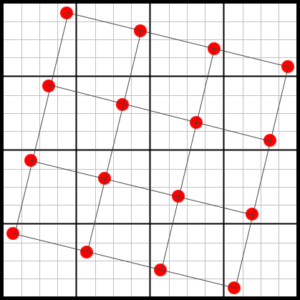
There are a couple of interesting things to note about this grid:
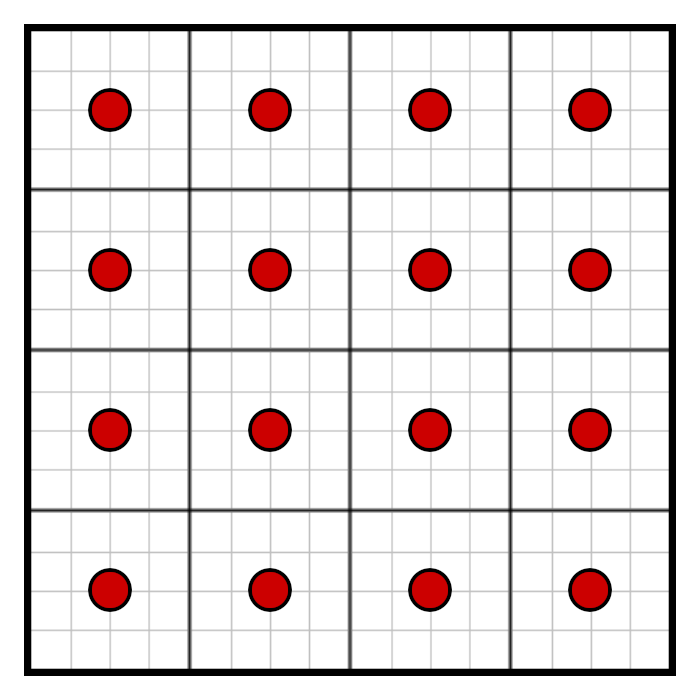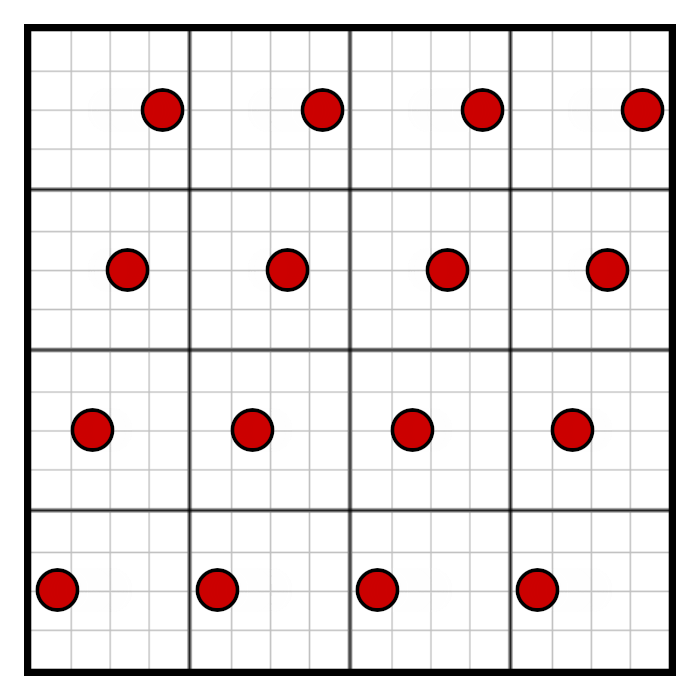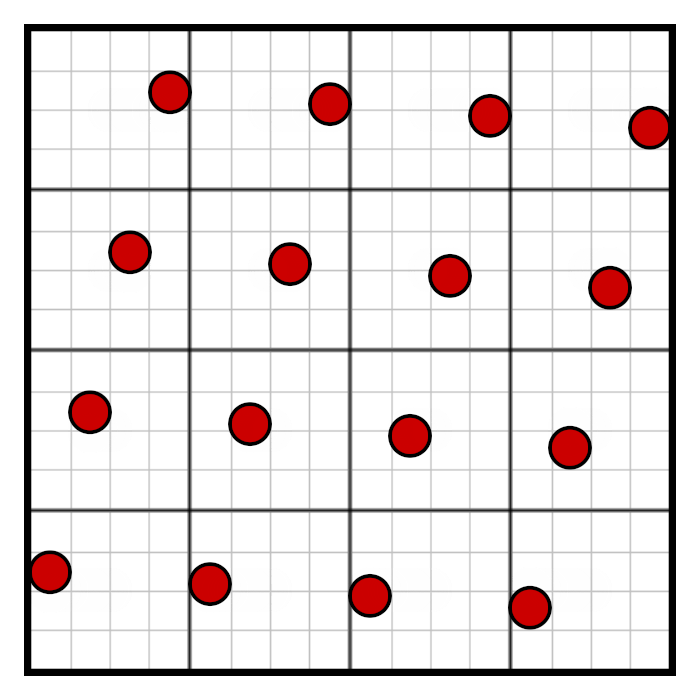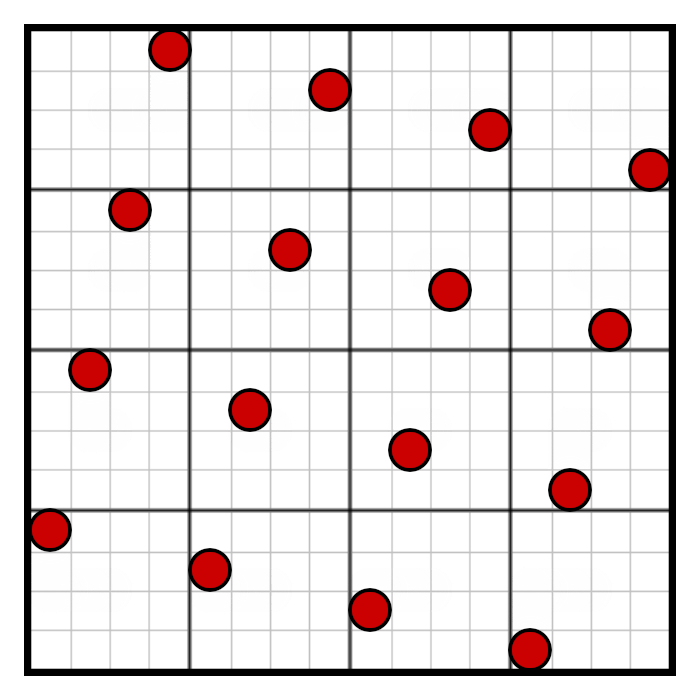
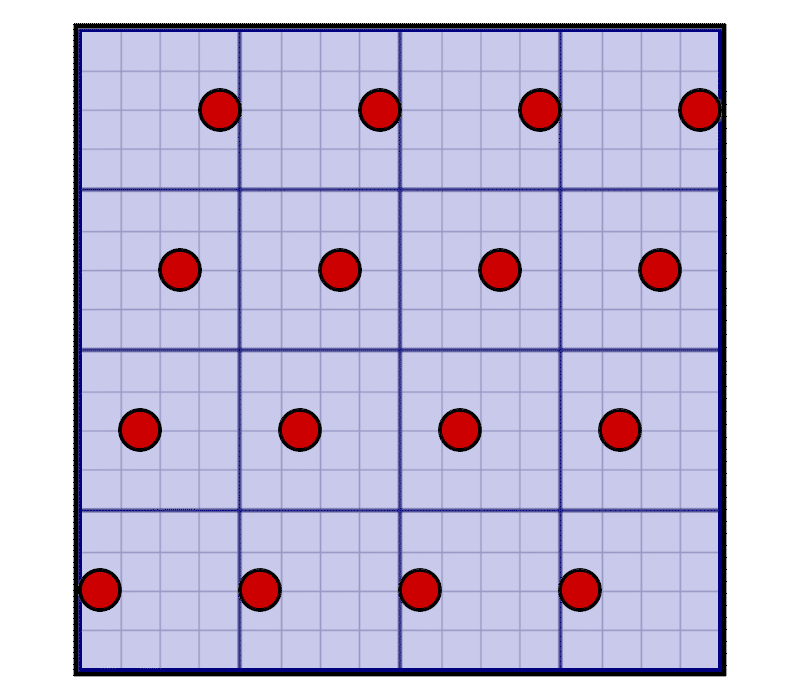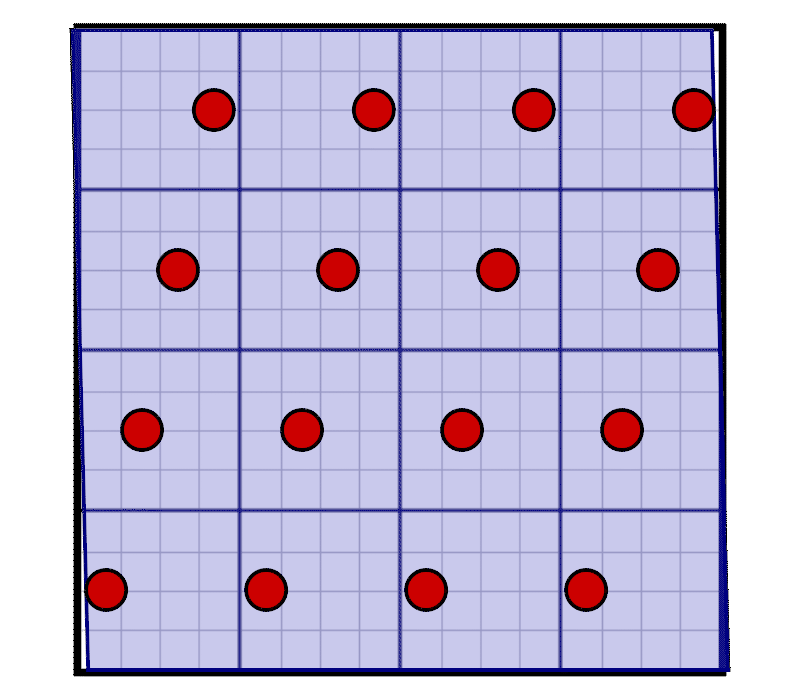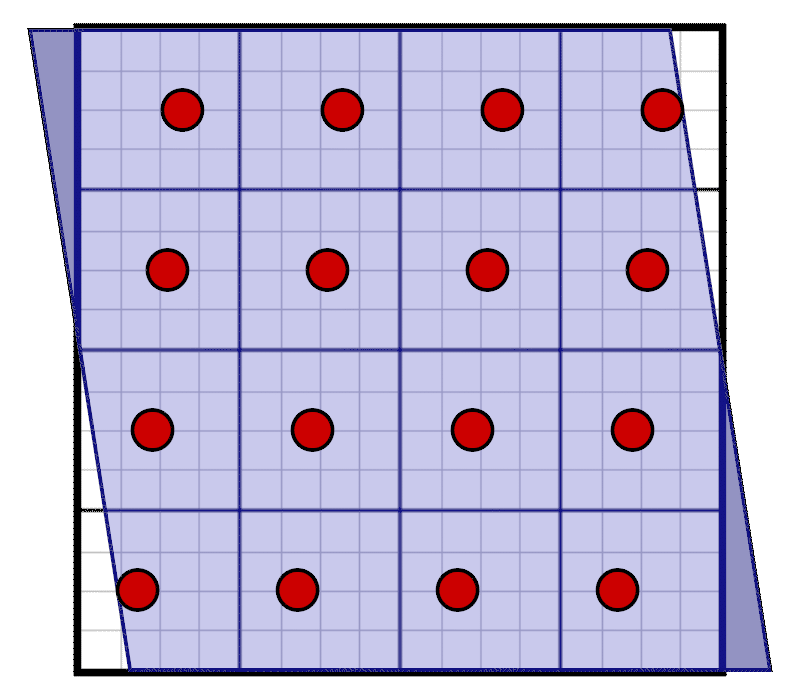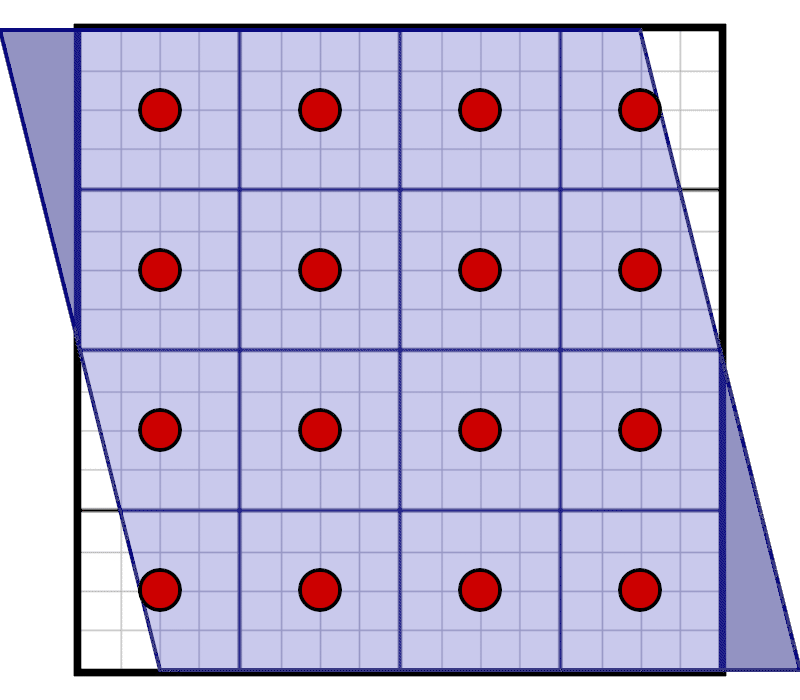
- There are 16 evenly spaced samples both in the horizontal and vertical direction.
- Compared to the regular grid, the samples are moved horizontally and vertically but never leave their cell from the original 4×4 grid.
During rasterization, we need to sample the glyph at the rotated grid’s positions instead of the center of the cell. How rasterization is performed and how these values are sampled will be discussed in part three. Here we assume that the 16 bits in the coverage mask are properly sampled at those positions and stored similarly as we did with the regular grid, in row major order:
We now need to solve the problem of counting bits that intersect the pixel window as shown in the following image:
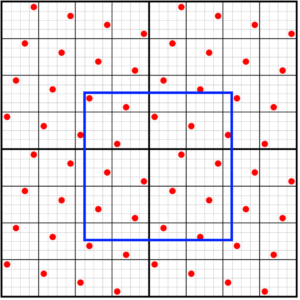
Although this image looks more intimidating than a regular grid, we should remember that the 4×4 row and column positions didn’t actually change, we’ve just offset them differently within the row and column. The key realization here is that the grid rotation can be decomposed into a separate horizontal and vertical skew, as shown in the following animation:
We can use this horizontal skew and vertical skew to adjust our masking.
Horizontal masking
Our coverage mask is still stored in the same way as we used to store it for the regular grid, it is only sampled at a different position. During evaluation we now need to correct for the rotation. Instead of performing the horizontal skew on the coverage mask itself, we are going to perform the inverse skew on the pixel mask. This is displayed in the following animation:
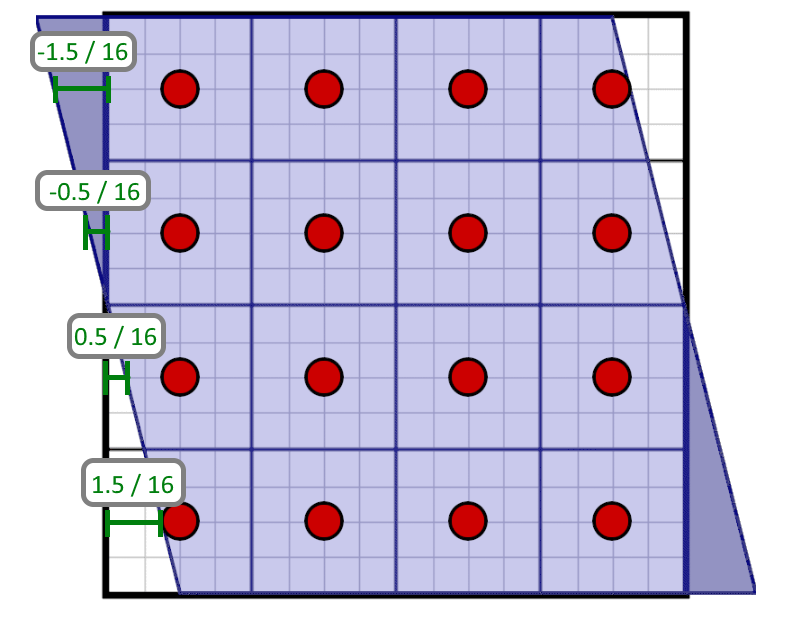
For each row of a texel, we can see how we need to adjust the shift of the pixel window:
On a 2×2 texel grid, the pixel window and the skewed horizontal pixel mask looks like this:

In this animation we see a blue pixel window moving to the right. The weights for the top and bottom texels are skewed as explained – this is indicated by the red and green areas. The green area indicates the area where bits need to be enabled, and the red area indicates where bits need to be zeroed out. You can see that for a glyph with straight edges, the samples pop on and off much more frequently, which is why we see more shades.
In code, we need to compute a horizontal mask for each texel row using the offsets:
int row0RightShift = int(round((weight.x - (1.5 / 16.0)) * 4.0)); int row1RightShift = int(round((weight.x - (0.5 / 16.0)) * 4.0)); int row2RightShift = int(round((weight.x + (0.5 / 16.0)) * 4.0)); int row3RightShift = int(round((weight.x + (1.5 / 16.0)) * 4.0));
Using the shifts for each row, we can calculate the pixel mask, again separating the 0xF0 pixel mask for the left and right texels.
uint leftRow0pixelMask = (0x0Fu >> row0RightShift); uint leftRow1pixelMask = (0x0Fu >> row1RightShift); uint leftRow2pixelMask = (0x0Fu >> row2RightShift); uint leftRow3pixelMask = (0x0Fu >> row3RightShift); uint rightRow0pixelMask = (0x0F0u >> row0RightShift) & 0xFu; uint rightRow1pixelMask = (0x0F0u >> row1RightShift) & 0xFu; uint rightRow2pixelMask = (0x0F0u >> row2RightShift) & 0xFu; uint rightRow3pixelMask = (0x0F0u >> row3RightShift) & 0xFu; uint leftMask = (leftRow0pixelMask << 12) | (leftRow1pixelMask << 8) | (leftRow2pixelMask << 4) | leftRow3pixelMask; uint rightMask = (rightRow0pixelMask << 12) | (rightRow1pixelMask << 8) | (rightRow2pixelMask << 4) | rightRow3pixelMask;
The masks for the top and bottom texels are the same, so we copy them into the higher bits:
leftMask = (leftMask << 16) | leftMask; rightMask = (rightMask << 16) | rightMask;
And that’s it for the horizontal mask. In case you were wondering if the negative weights for the first two rows can cause negative shift values: they can’t. The most negative value is -1.5, so:
-1.5/16.0*4.0 = -3/8
If you recall from part one, the rounding in the shift calculation is required to move the mask only when it crosses sample positions. This rounding will also cause the negative value to snap to zero if smaller than ½, which is the case for our most negative value (-3/8). As the value approaches zero, the value will only get smaller, so between -1.5 and 0, the rounded value remains zero and will never be negative.
Our intermediate render using a rotated grid now looks like this:

You can already see how we now have 16 different shades in the horizontal direction.
Vertical masking
The vertical masking has a bit of a climax to it. A lot of the choices that have been made so far enable us to perform this vertical masking very easily. By combining the left texels and the right texels to form two 32-bit values, we can see that a single column of texels form a perfectly sorted, evenly spaced list of vertical samples:
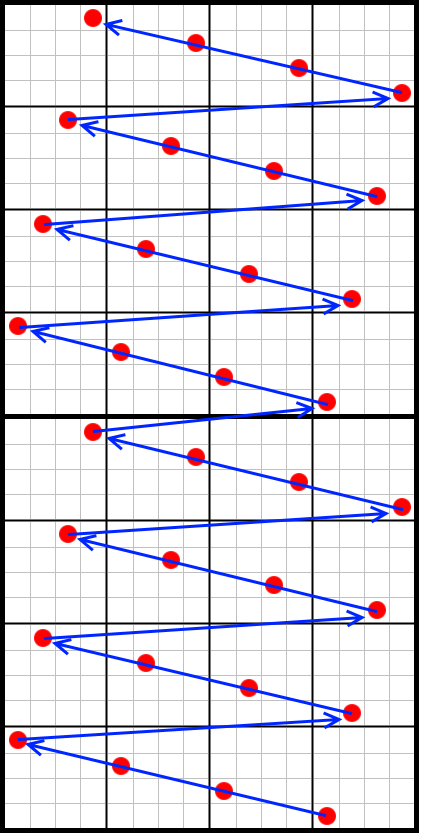
In this image you can see two texels forming a combined 32-bit value. The blue arrows indicate the order in which the bits are stored: from bottom to top. In this 16×32 grid, each sample occupies one unique row, ordered from bottom to top, spaced evenly. All we need to do now is create a mask consisting of four full rows (which is 0xFFFF) and linearly shift it along with the pixel window position:
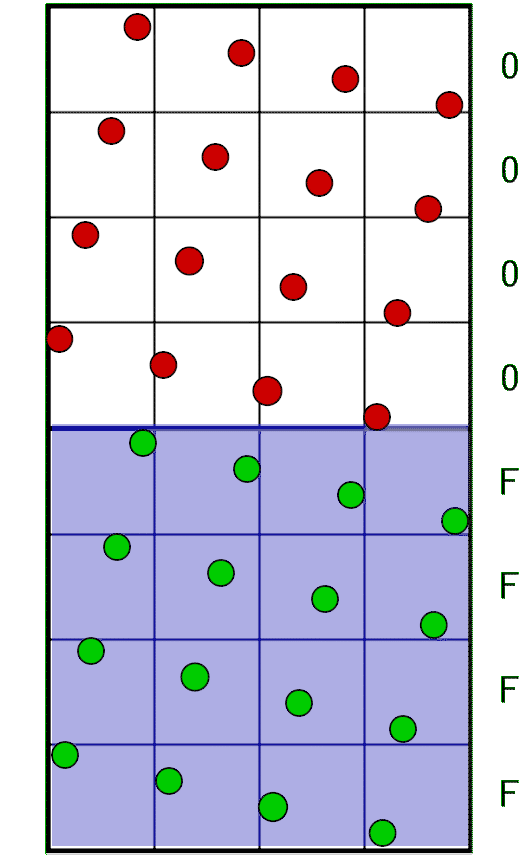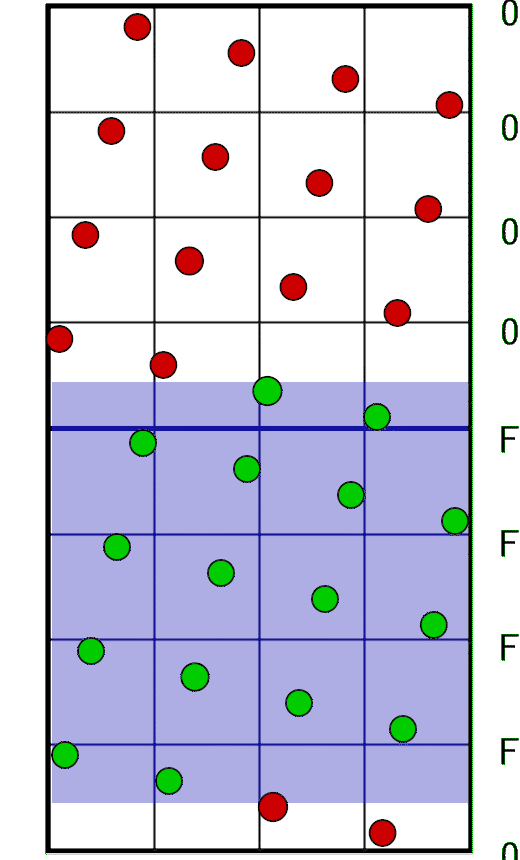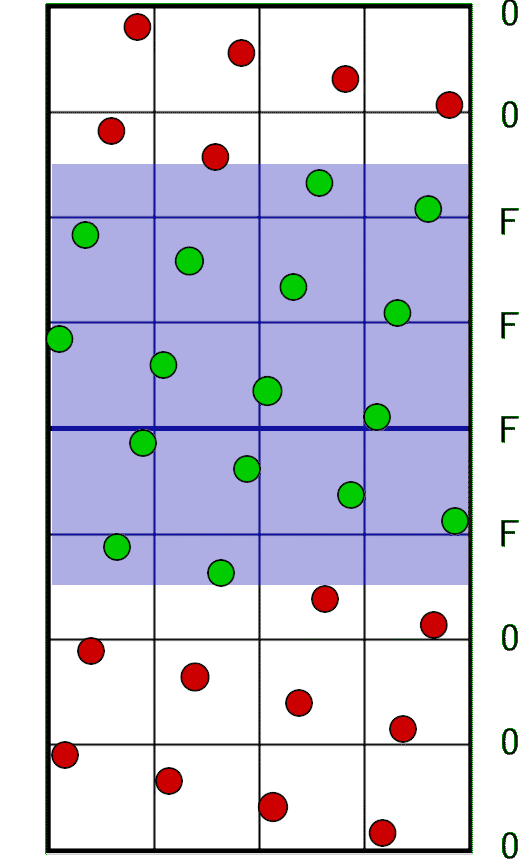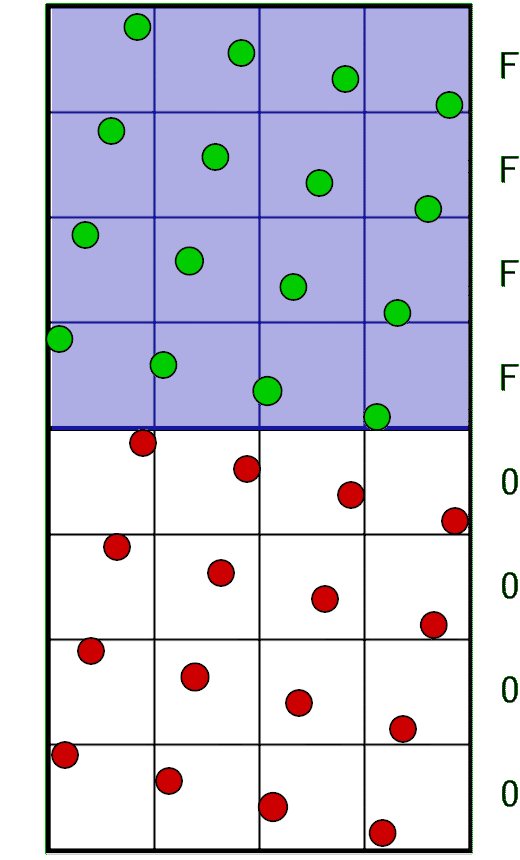
In code:
int shift = int(round(weight.y * 16.0)); uint verticalMask = 0xFFFF << shift;
The masking can now be performed using two AND operations, one horizontal and one vertical mask:
uint left = ((topLeft << 16) | leftBottom) & leftMask & verticalMask; uint right = ((topRight << 16) | rightBottom) & rightMask & verticalMask;
And that’s it! we’re done. Out letter ‘T’ now looks like this:

It may not be that apparent, but some of the choices we made in the first part of this series allowed us to do this simple vertical shift. It’s the combining of the left texels and the right texels that allow us to view the 32-bit value as a sorted list, and it’s the row-major ordering of our storage as well. A less obvious factor is the way we’re clearing bits. By using a pixel mask, we only zero out bits outside the pixel window. As a result, the coverage bits never move in position. Alternatively, we could have tried to shift the coverage mask directly, but that could alter their vertical position during the shifting for rotated grids, causing the vertical sorting to break.
Collapsing the math into a table
So far we have taken a pixel window position (a weight) and calculated a horizontal and vertical mask out of it and then we used that mask to zero bits out. Because there is a finite amount of unique mask values, we can precalculate them and put them in a lookup table.
To see the amount of possible mask values, let’s look at the horizontal mask:
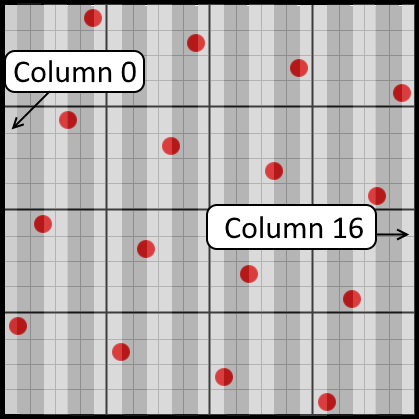
In this image, the gray columns indicate the different mask values. Notice that the mask changes value at the center of a sample. So, the very first and last column have a width of 1/32th of a texel, and the other columns have a width of 1/16th of a texel. Although the rotated grid gives you 16 shades in the horizontal and vertical direction, we have 17 distinct mask values in both the horizontal and vertical direction. The easiest mapping from weight to mask is to divide the texel into a 32×32 grid.
Because the horizontal masks for left and right texels are different (discussed in part one), we make a horizontal-left and horizontal-right table. To build the horizontal table we go over our 32 entries and just call the code as we’ve built it up so far:
void CalcValues(float weightX, unsigned int& inLeft, unsigned int& inRight)
{
// Compute horizontal bit shifts, accounting for horizontal shift due to rotated grid
int row0RightShift = int(round((weightX - (1.5 / 16.0)) * 4.0));
int row1RightShift = int(round((weightX - (0.5 / 16.0)) * 4.0));
int row2RightShift = int(round((weightX + (0.5 / 16.0)) * 4.0));
int row3RightShift = int(round((weightX + (1.5 / 16.0)) * 4.0));
unsigned int leftRow0pixelMask = (0x0F >> row0RightShift);
unsigned int leftRow1pixelMask = (0x0F >> row1RightShift);
unsigned int leftRow2pixelMask = (0x0F >> row2RightShift);
unsigned int leftRow3pixelMask = (0x0F >> row3RightShift);
unsigned int rightRow0pixelMask = (0x0F0 >> row0RightShift) & 0xF;
unsigned int rightRow1pixelMask = (0x0F0 >> row1RightShift) & 0xF;
unsigned int rightRow2pixelMask = (0x0F0 >> row2RightShift) & 0xF;
unsigned int rightRow3pixelMask = (0x0F0 >> row3RightShift) & 0xF;
unsigned int leftMask = (leftRow0pixelMask << 12) | (leftRow1pixelMask << 8) | (leftRow2pixelMask << 4) | leftRow3pixelMask;
unsigned int rightMask = (rightRow0pixelMask << 12) | (rightRow1pixelMask << 8) | (rightRow2pixelMask << 4) | rightRow3pixelMask;
inLeft = leftMask;
inRight = rightMask;
}
void CalcFontShaderTable()
{
unsigned int leftMaskTable[32];
unsigned int rightMaskTable[32];
for (int i = 0; i != 32; ++i)
{
float weightX = (float)(i / 32.0f);
CalcValues(weightX, leftMaskTable[i], rightMaskTable[i]);
}
}
This will give us a table for a single texel. We can copy the lower bits to the upper 16 bits to make it a mask for two texels, forming an entire 32 bit value. The full horizontal tables then look like this:
uint leftMaskTable[] = uint[] ( 0xffffffffu, 0xfff7fff7u, 0xfff7fff7u, 0xff77ff77u, 0xff77ff77u, 0xf777f777u, 0xf777f777u, 0x77777777u, 0x77777777u, 0x77737773u, 0x77737773u, 0x77337733u, 0x77337733u, 0x73337333u, 0x73337333u, 0x33333333u, 0x33333333u, 0x33313331u, 0x33313331u, 0x33113311u, 0x33113311u, 0x31113111u, 0x31113111u, 0x11111111u, 0x11111111u, 0x11101110u, 0x11101110u, 0x11001100u, 0x11001100u, 0x10001000u, 0x10001000u, 0x00000000u ); uint rightMaskTable[] = uint[] ( 0x00000000u, 0x00080008u, 0x00080008u, 0x00880088u, 0x00880088u, 0x08880888u, 0x08880888u, 0x88888888u, 0x88888888u, 0x888c888cu, 0x888c888cu, 0x88cc88ccu, 0x88cc88ccu, 0x8ccc8cccu, 0x8ccc8cccu, 0xccccccccu, 0xccccccccu, 0xccceccceu, 0xccceccceu, 0xcceecceeu, 0xcceecceeu, 0xceeeceeeu, 0xceeeceeeu, 0xeeeeeeeeu, 0xeeeeeeeeu, 0xeeefeeefu, 0xeeefeeefu, 0xeeffeeffu, 0xeeffeeffu, 0xefffefffu, 0xefffefffu, 0xffffffffu );
In this table you can see how the first and last entry are unique, and that the other values are duplicated side by side, forming 17 distinct values.
Putting the vertical mask into a table doesn’t yield the same amount of simplification as it is already very simple in its runtime form – one might decide to leave the vertical table out. Here’s the code to build the table:
unsigned int CalcYValue(float inWeight)
{
int shift = int(round(inWeight * 16.0));
return 0xFFFF << shift;
}
void CalcFontVerticalTable()
{
unsigned int verticalMaskTable[32];
for (int i = 0; i != 32; ++i)
{
float weightY = (float)(i / 32.0f);
verticalMaskTable[i] = CalcYValue(weightY);
}
}
And the table then looks like this:
uint verticalMaskTable[] = uint[] ( 0x0000ffff, 0x0001fffe, 0x0001fffe, 0x0003fffc, 0x0003fffc, 0x0007fff8, 0x0007fff8, 0x000ffff0, 0x000ffff0, 0x001fffe0, 0x001fffe0, 0x003fffc0, 0x003fffc0, 0x007fff80, 0x007fff80, 0x00ffff00, 0x00ffff00, 0x01fffe00, 0x01fffe00, 0x03fffc00, 0x03fffc00, 0x07fff800, 0x07fff800, 0x0ffff000, 0x0ffff000, 0x1fffe000, 0x1fffe000, 0x3fffc000, 0x3fffc000, 0x7fff8000, 0x7fff8000, 0xffff0000 );
That simplifies the entire masking operation in the shader into:
uint leftMask = leftMaskTable[int(weight.x * 32.0f)]; uint rightMask = rightMaskTable[int(weight.x * 32.0f)]; uint verticalMask = verticalMaskTable[int(weight.y * 32.0f)]; uint left = ((topLeft << 16) | leftBottom) & leftMask & rightMask; uint right = ((topRight << 16) | rightBottom) & rightMask & rightMask;
It is of course possible to combine the horizontal and vertical masks as well, eliminating the AND that is required for the vertical mask. That would mean that the two horizontal tables would consist out of 32×32=1024 values. However, the separated masks are quite compact and somewhat ‘readable’: you can see the bit shifting pattern in them and how they consist of these 17 distinct values in both directions. For these reasons I personally prefer the compact tables instead.
Next time…
This concludes the rendering part. Next time we’ll see how we actually rasterize and generate those glyphs. See you next time!
Follow us on twitter @SuperluminalSft.

2 Comments
Great write-up, very clear, some smart stuff here.
One thing that concerns me is that the rotated sample grid seems like it will play poorly with italics and other sloped shapes. (You could reverse the rotation to improve italics, but then backslash in some fonts will be bad.) Since you’re already using a mask table, maybe instead of a rotated grid you should use a semi-random grid. To maintain the current performance, given that you’re using precomputed tables anyway, just have 16 sub-sample rows, each with one sample somewhere on it, but instead of computing with a skew, just precompute a pseudo-random horizontal position for each row, or possibly even use the bit-reversed row index since that may maximize spread. (I.e. 0,8,4,12, etc.–a bit like classical dither.) Actually the first and last sample of that will be too close to each other across the wrapped border, so you probably need to find something smarter but blue-noisish. Could even just jitter your existing rotated positions.
Hi Sean,
Thanks for your comment! The rotated grid has the downside that even though rotated, straight lines could still align with the grid, causing fewer shades than we’d like. If I read your comment correctly, you’re suggesting to add a bit of noise to the samples to avoid that any straight line could ever align with the grid, is that correct?